
In this article, I will explain what is Hive Partitioning and Bucketing, the difference between Hive Partitioning vs Bucketing by exploring the advantages and disadvantages of each features with examples.

At a high level, Hive Partition is a way to split the large table into smaller tables based on the values of a column(one partition for each distinct values) whereas Bucket is a technique to divide the data in a manageable form (you can specify how many buckets you want)
Partitioning and bucketing are two different techniques used in distributed data processing systems such as Apache Spark. Here's the difference between them:
Partitioning: Partitioning is the process of splitting a large dataset into smaller, more manageable pieces called partitions. Each partition is stored on a separate node in the cluster, allowing for parallel processing of the data. Partitioning is useful for distributing the workload evenly across multiple nodes, and it helps to reduce the amount of data that needs to be processed in memory at any given time.
Bucketing: Bucketing is a technique used to group data based on a specific column or set of columns. It involves dividing the data into a fixed number of buckets based on the column values, such as date ranges or numeric intervals. The data in each bucket is then processed independently, allowing for more efficient processing of the data.
In summary, partitioning involves splitting a dataset into smaller partitions, while bucketing involves grouping data into buckets based on specific column values. Both techniques can be used to improve the performance of distributed data processing systems like Apache Spark.
- Partitioning in Spark:
Partitioning in Spark refers to dividing the data into smaller chunks called partitions, which are stored and processed in parallel across the nodes in the cluster. Partitioning is important for distributed processing because it enables Spark to split the work among multiple nodes, which can improve performance and scalability. Spark uses partitioning for various operations such as shuffling, sorting, and joining.
For example, let's say you have a dataset containing customer information with millions of records. You can partition the data by customer ID, so that all records with the same customer ID are grouped together in the same partition. This can help speed up queries and analysis that are performed on a specific customer's data.
Here's an example code for partitioning a DataFrame in Spark:
luadf = spark.read.format('csv').load('path/to/file.csv')
df = df.repartition(4, 'customer_id')
In this example, we read in a CSV file into a DataFrame df. Then, we repartition the DataFrame into four partitions based on the customer_id column. This means that the data will be split into four partitions, with records for the same customer ID stored together in the same partition.
- Bucketing in Spark:
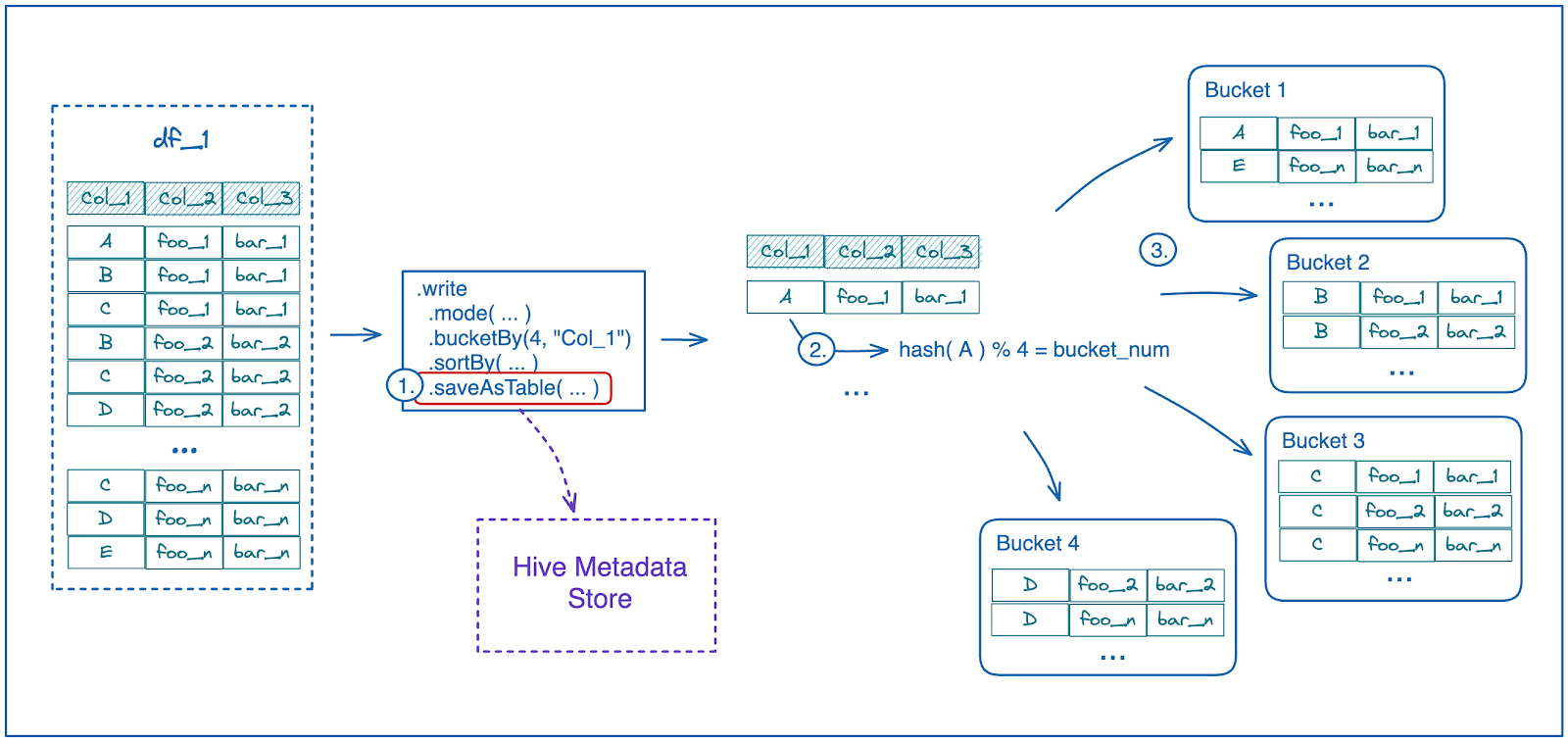
Bucketing in Spark is a technique for organizing data based on a specific column or set of columns. Instead of dividing the data into partitions based on a hash function, as in partitioning, bucketing divides the data into a fixed number of buckets based on the values of a specific column. The goal of bucketing is to group related data into the same bucket, which can improve performance for certain types of queries.
For example, let's say you have a dataset containing sales information for a retail store, with millions of records. You could bucket the data by product ID, so that all sales data for a specific product are grouped together in the same bucket. This can help speed up queries that require analysis of sales data for specific products.
Here's an example code for bucketing a DataFrame in Spark:
luadf = spark.read.format('csv').load('path/to/file.csv')
df.write.bucketBy(4, 'product_id').saveAsTable('sales_data')
In this example, we read in a CSV file into a DataFrame df. Then, we use the bucketBy() function to create four buckets based on the product_id column, and save the bucketed DataFrame as a table named sales_data. This means that the data will be split into four buckets based on the product ID column, which can improve query performance for analysis that involves sales data for specific products.
In summary, partitioning and bucketing are both techniques used in Spark for organizing and processing data, but they serve different purposes. Partitioning divides the data into smaller partitions for distributed processing, while bucketing groups related data into fixed-size buckets for improved query performance.
No comments:
Post a Comment
Thanks for your comments